Ripper Web Content | Capture Metadata Contentリッパーウェブコンテンツ | メタデータコンテンツのキャプチャ
Ripper Web Contentは、Web上で見つかるコンテンツからメタデータを分析・抽出することができる多機能なChrome拡張機能です。この無料ツールは、デジタルフォレンジックス、調査環境、オープンソースインテリジェンス(OSINT)の分野で貴重な資産となります。
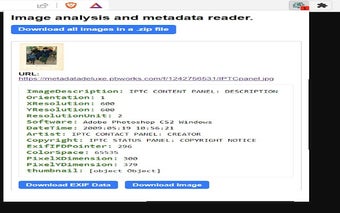
Ripper Web Contentを使用すると、ユーザーは画像のメタデータを取得・ダウンロードすることができ、さまざまなコンテキストで画像を分析するための必須ツールとなります。この拡張機能は、Google LensとTinEyeを使用して逆画像検索を行う機能も提供しており、ユーザーは画像の元のソースを特定したり、オンラインで類似の画像を見つけることができます。
Ripper Web Contentの特徴の1つは、FotoForensicsとの統合です。これにより、ユーザーは画像を潜在的な改ざんや操作の可能性について分析することができ、調査作業で画像の信頼性を検証するのに役立つツールとなります。
この拡張機能は、顔検出機能も提供しており、写真内の人数、性別、年齢、気分などの情報を提供します。この機能は、個人の特定や表情からの洞察を得るために特に有用です。
画像の分析に加えて、Ripper Web ContentはPDF、DOCX、PPTX、XLSXなどのさまざまなドキュメント形式からメタデータをスキャン・抽出することも可能です。この機能により、Web上で見つかるドキュメントから素早く効率的に情報を収集することができます。
全体として、Ripper Web ContentはWebコンテンツからメタデータを分析・抽出するための強力かつ包括的なツールです。その機能の幅広さにより、デジタルフォレンジックス、調査、OSINTの作業において貴重な資産となります。